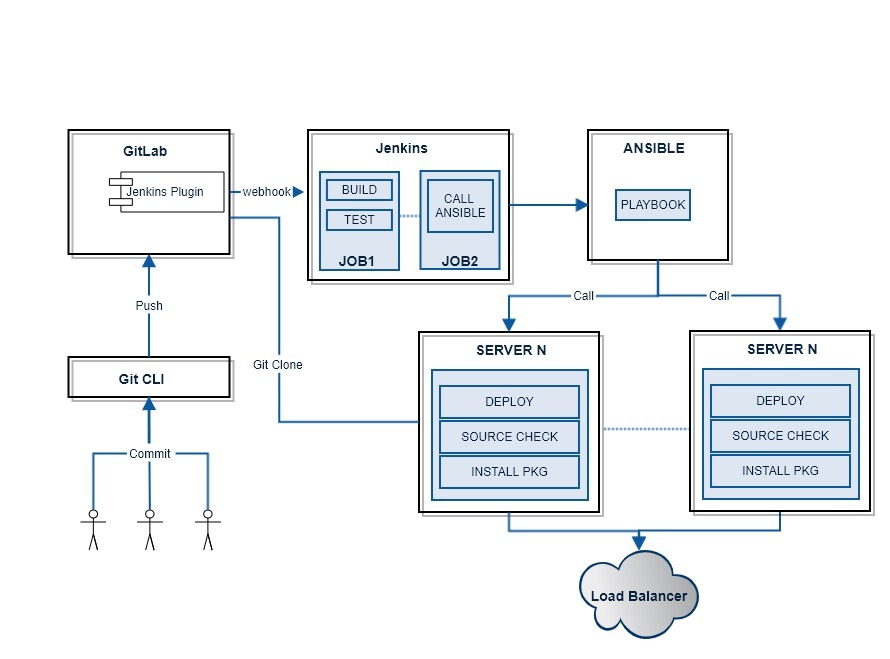
CI/CD Automation Architecture
1 | yum install http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm |
1 | curl -O https://releases.ansible.com/ansible-tower/setup/ansible-tower-setup-latest.tar.gz |
https://[serverIP]:80
admin / password(inventory에서 설정한 pw)
1 | [root@tcid]# tower-manage changepassword admin |
1 | yum list java*jdk-devel |
1 | wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo |
http://www.rabbitmq.com/direct-reply-to.html
링크 발췌내용 중 사용법
Use
To use direct reply-to, an RPC client should:
Consume from the pseudo-queue amq.rabbitmq.reply-to in no-ack mode. There is no need to declare this “queue” first, although the client can do so if it wants.
Set the reply-to property in their request message to amq.rabbitmq.reply-to.
The RPC server will then see a reply-to property with a generated name. It should publish to the default exchange (“”) with the routing key set to this value (i.e. just as if it were sending to a reply queue as usual). The message will then be sent straight to the client consumer.
If the RPC server is going to perform some expensive computation it might wish to check if the client has gone away. To do this the server can declare the generated reply name first on a disposable channel in order to determine whether it still exists. Note that even if you declare the “queue” with passive=false there is no way to create it; the declare will just succeed (with 0 messages ready and 1 consumer) or fail.
결론적으로 클라이언트에서 consume(대기큐)를 할때 옵션으로 reply-to = amq.rabbitmq.reply-to 넣고 no-ack 모드로 실행한다.
그러면 따로 큐를 생성해 놓지 않더라도 amq.rabbitmq.reply-to 라는 큐가 생성되고 서버에서는 reply-to property를 통해 클라이언트에게 리턴한다.
서버에서 특이점은 publish 할때 따로 exchange name 을 적지 않고 routingkey 자리에 reply-to에서 온 값을 넣으면된다.
서버에서 reply-to 리턴하는 queue를 찍어보면 amq.rabbitmq.reply-to.g2dkAA1yYWJiaXRAdHdlYjAyAAAvugAAAAMB.N2mDRUJksXuxZHf1leTCKg==
이런식으로 뒤에 임의의 값이 붙어서 나온다. 여러 서버를 띄어도 저 값은 변하지 않았다. rabbitmq 서버에서 관리하는 것으로 보인다.
reply-to 옵션을 쓰지않고 지정된 큐로 작업이 가능하다.
ack모드를 사용할수있어 데이터 유지하는 옵션을 사용할수있다.
하지만 옵션을 사용시 rabbitmq에서 제공하는 큐생성 및 사용시 추가적인 작업이 필요해 보인다.
메시지를 Queue에 넣은 뒤 Consumer에게 전달하기 전에 RabittMQ 서버가 죽는다면 기본적으로 해당 메시지는 날라가버리게 된다. 이런 상황을 방지 하기 위해 durable이라는 개념을 가지고 있다.
Message durability
메시지는 Queue에 보관할 때 file에도 같이 쓰도록 만드는 방법이다.
아래와 같은 방법으로 설정해야 동작한다.
queue생성시 durable속성을 true로 주고 만든다.
message publish할때 MessageProperties.PERSISTENT_TEXT_PLAIN을 설정함
1,2번 모두 만족해야 메시지가 Queue에 남아있을 때 restart해도 날라가지 않는다.

※ 메시지의 persistent는 완변히 보장되진 않음. 메번 메시지마다 fsync 로 동기화히지 않기 때문에 짧은시간이나마 아직 Disk에 쓰여지지 않았을 경우가 있다. 좀더 강력한 방법을 보장하기 위해서는 publisher confirms를 사용
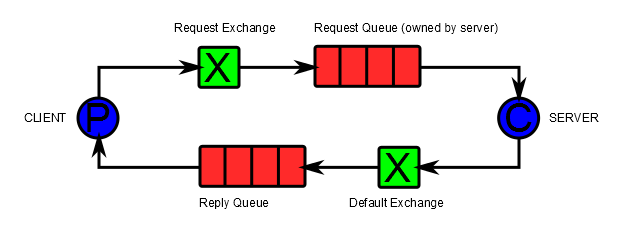
RabbitMQ는 Request-Response로 Client와 Server를 이어주기 위해 RPC라는 개념으로 기능을 제공한다.
RPC라는 거창한 이름을 사용하였지만 실제로는 Client의 request를 Server에 전달하고 , Server가 처리한 결과를 알맞은 Client 요청에 대한 응답으로 전달 할 수 있는 방법을 말한다.
Message Properties 설명
DeliveryMode : persistent인지 transient인지 표시 (휘발성인지 비휘발성인지 구분자)
ContentType : 내용물의 mime-type
ReplyTo : Callback Queue의 이름
CorrelationID : 요청을 구분할 수 있는 유일값
처리 흐름
Client가 CorrelationID, ReplyTo 주어서 RabbitMQ의 특정 Request보관용 Queue에 데이터를 Push한다.
Request용 Queue에 데이터를 Server에서 Consume하여 요청을 처리한다.
요청처리 후 Request에서 받은 CorrelationID 와 ReplyTo를 추출하여, 요청ID를 속성으로 갖는 Response를 ReplyToQueue에 Push한다.
Client는 ReplyTo Queue를 subscribe하고 있다가 Response가 오면 CorrelationID를 보고 어떤 요청에 대한 응답인지를 구분하여 처리한다.
RPC 구조를 응용하면 아래와 같은 상황에 이점을 얻을 수 있다.
서버처리 이점
서버 처리속도가 느려서 성능을 증가 시키려고 할 때, RPC 서버를 하나 더 두고 같은 Request Queue를 바라보게 하면 됨 ( Round Robin 하므로 )
Client 이점
하나의 메시지를 개별 Round Trip으로 처리를 위해 queueDeclare같은 동기처리 요청이 필요없다. (임시 Queue를 생성하여 Client마다 다른 Queue를 사용하므로)
RPC 구성시 고려할 점
돌아가는 서버가 없을 때 Client 처리
요청 Timeout시 Client 처리
서버 Exception이나 오동작시 Client에게 이를 어떻게 전달할지
Invalid한 데이터가 서버로 전달 되었을 때의 처리
작업을 수행하는 데 몇 초가 걸릴 수 있습니다.
소비자 중 한 명이 긴 작업을 시작하고 부분적으로 만 수행되어 사망하는 경우 어떻게되는지 궁금 할 수 있습니다.
현재의 코드(
noAck : true
)를 사용하면 RabbitMQ가 고객에게 메시지를 전달하면 바로 삭제 표시가됩니다.
이 경우 작업자를 죽이면 처리중인 메시지가 손실됩니다.
이 특정 작업자에게 발송되었지만 아직 처리되지 않은 모든 메시지도 손실됩니다.
noAck : false
ack를 전송하지 않고 소비자가 죽거나 (채널이 닫히거나 연결이 끊어 지거나 TCP 연결이 끊어지는 경우),
RabbitMQ는 메시지가 완전히 처리되지 않았 음을 인식하고 다시 대기합니다.
가끔씩 사망하더라도 메시지를 잃어 버리지 않을 것입니다.
메시지 시간 초과가 없습니다. RabbitMQ는 소비자가 사망 할 때 메시지를 재전송합니다.
메시지 처리가 매우 오랜 시간이 걸리는 경우에도 괜찮습니다.
앞의 예에서 메시지 수신 확인이 해제되었습니다. 작업을 마친 후 에는 noAck : false
옵션 을 사용하여 설정을 해제하고 작업자에게 적절한 응답을 보내야합니다.
ex) 자동 응답
ch.consume(q, function(msg) {
var secs = msg.content.toString().split(‘.’).length - 1;
console.log(“ [x] Received %s”, msg.content.toString());
setTimeout(function() {
console.log(“ [x] Done”);
}, secs * 1000);
}, {noAck: true});
ex) 자동 미응답 & ack(msg)
ch.consume(q, function(msg) {
var secs = msg.content.toString().split(‘.’).length - 1;
console.log(“ [x] Received %s”, msg.content.toString());
setTimeout(function() {
console.log(“ [x] Done”);
ch.ack(msg);
}, secs * 1000);
}, {noAck: false});
우리는 소비자가 사망하더라도 작업이 손실되지 않도록하는 방법을 배웠습니다. 그러나 RabbitMQ 서버가 중지되면 우리의 작업은 여전히 손실됩니다.
RabbitMQ가 종료되거나 충돌하면 사용자가 알리지 않는 한 대기열과 메시지를 잊어 버리게됩니다. 메시지가 손실되지 않도록하려면 큐와 메시지를 모두 튼튼하게 표시해야합니다.
첫째, 우리는 RabbitMQ가 결코 우리 큐를 잃지 않도록해야합니다. 그렇게하기 위해서 우리는 그것을 durable 으로 선언 할 필요가있다 .
ex)
큐 할당시
ch.assertQueue ( ‘hello’ , { durable : true });
큐로 전송시 옵션
ch.sendToQueue(q, new Buffer(msg), {persistent: true});
new_task.js1
2
3
4
5
6
7
8
9
10
11
12
13
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'task_queue';
var msg = process.argv.slice(2).join(' ') || "Hello World!";
ch.assertQueue(q, {durable: true});
ch.sendToQueue(q, new Buffer(msg), {persistent: true});
console.log(" [x] Sent '%s'", msg);
});
setTimeout(function() { conn.close(); process.exit(0) }, 500);
});
worker.js
1 |
|
기본적으로 noAck, durable 옵션으로 큐에서의 삭제와 ack의 사용을 조정할수있다.
로그를 쌓는 서비스를 예를 들어보면
보내는(pub)서버와 처리하는(subs)서버가 있겠다.
pub에서 메세지를 보내고 큐에 쌓인다. subs 서버는 이를 하나씩 꺼내어 처리한다.
큐에 보낸 메세지를 잃어 버리지 않기 위해서는 durable 옵션으로 큐를 생성하고
큐에 전송시 persistent 옵션을 주면된다.
그러면 rabbitmq가 죽더라고 큐에 들어간 내용들은 재기동시 다시 살아난다.
하지만 subs서버가 큐에서 꺼낸 메세지를 작업중 죽는다면 메세지는 소실된다.
이를 위해 consume함수 옵션(noAck)을 사용한다. 기본적으로 noAck를 하면 자동으로 ack가 실행되고
큐에서 사라진다. 하지만 noAck 옵션을 false로 선언하면 subs서버에서 작업을 처리한후 ack를 보내야한다.

The RPC client must consume in no-ack mode.
This is because there is no queue for the reply message to be returned to
if the client disconnects or rejects the reply message.
RPC 클라이언트는 반드시 consume을 사용할 때 no-ack 모드를 사용해야한다.
클라이언트에서 연결이 끊기거나 reject 에러가 나면 서버에서 전달할 방법이 없기 때문이다.
reply queue는 요청시 생성되고 결과받고 사라지는 임시큐이다.
메세지가 유실되면 안되는 서비스의 처리는 별도로 처리하는 것이 맞겠다.
개발자와 운영자간에 충돌을 해결하기 위한 방법론
개발과 운영 간의 프로세스와 도구에 대한 접근을 공유하여 그 차이를 줄이는데 목적을 둔다.
개발자와 운영자의 업무뿐만 아니라 QA업무(TEST)에도 포함
Devops란, “엔지니어가, 프로그래밍하고, 빌드하고, 직접 시스템에 배포 및 서비스를 RUN한다. 그리고, 사용자와 끊임 없이 Interaction하면서 서비스를 개선해 나가는 일련의 과정이자 문화이다.”
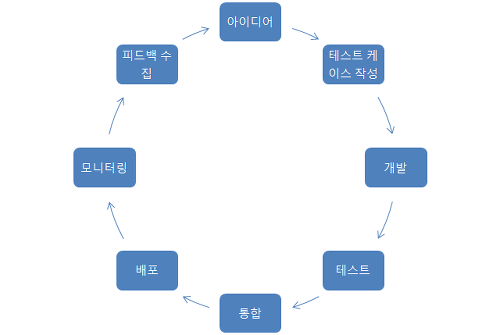
기존 개발팀은 기획팀이 요구사항을 개발팀에 던지고, 개발팀은 개발 내용을 운영에 던지는, waterfall 모델 처럼, 각 팀이 개발 단계별로 자기 역할을 한 후에, 다음 단계로 던지고 잊어 버리는 (fire & forget) 형태라면, Devops 형태의 개발팀은, 던지는 것이 아니라 과정 내내 같이 수행한다. 요구 사항을 개발팀에 넘겨도, 개발팀과 계속 협의를 하면서 요구 사항을 구체화 하고, 개선하며, 개발중에 운영인원과 같이 협의 하면서 최적의 구조를 논의 하면서 개발이 진행된다.
지속적 통합은 자동화된 빌드 및 테스트가 수행된 후, 개발자가 코드 변경 사항을 중앙 리포지토리에 정기적으로 병합하는 소프트웨어 개발 방식입니다. 지속적 통합의 핵심 목표는 버그를 신속하게 찾아 해결하고, 소프트웨어 품질을 개선하고, 새로운 소프트웨어 업데이트를 검증 및 릴리스하는 데 걸리는 시간을 단축하는 것입니다.
필수요소 = CI 서버(젠킨스) + SCM(GIT) + 빌드툴 + 테스트툴(JUnit, Mocha)
지속적 전달은 코드 변경이 프로덕션에 릴리스할 수 있도록 자동으로 빌드, 테스트 및 준비되는 소프트웨어 개발 방식입니다. 빌드 단계 이후의 모든 코드 변경 사항을 테스트 환경 및/또는 프로덕션 환경에 배포함으로써 지속적 통합을 확장합니다. 지속적 전달이 적절하게 구현되면, 개발자는 언제나 즉시 배포할 수 있고 표준화된 테스트 프로세스를 통과한 빌드 아티팩트를 보유하게 됩니다.
배포툴(ANSIBLE and ANSIBLE Tower)
빌드 서버로 코드를 푸쉬 한 후 자동으로 빌드가 시작 되는 지점까지는 CI라 하며, 거기서 테스트를 거쳐 디플로이 과정까지 자동화가 되어있으면 CD라 한다 CD에서 또한 Deploy를 자동으로 해주냐, 수동으로 해주냐에 따라 Delivery, Deployment로 나뉘어집니다.
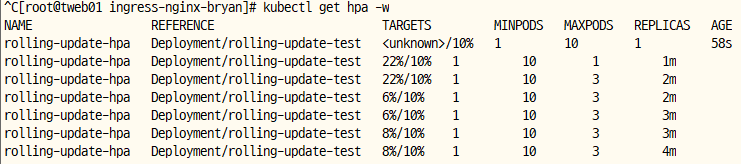
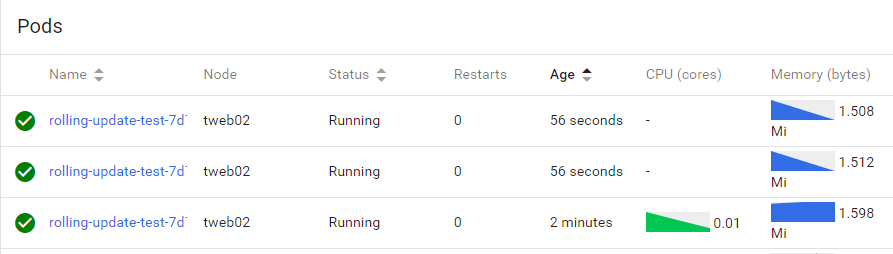
CPU 자원설정에 따라 자동으로 pod의 숫자를 scale-up 한다.
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: rolling-update-test
labels:
app: web-front-end
spec:
replicas: 1
minReadySeconds: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 50%
selector:
matchLabels:
app: web-front-end
template:
metadata:
labels:
app: web-front-end
department: group3
spec:
containers:
- name: m-client-rolling
image: skarl/client:latest
env:
- name: PORT_ARGS
value: "--port=80"
ports:
- containerPort: 80
name: web-port
protocol: TCP
resources:
requests:
memory: "256Mi"
cpu: "200m"
limits:
memory: "1Gi"
cpu: "500m"
Resources Requests 사용량 설정 필수
resources.requests.cpu 부분에 CPU 자원을 200m(milli-cores) 또는 0.2로 요청
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: rolling-update-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1beta2
kind: Deployment
name: rolling-update-test
maxReplicas: 10
minReplicas: 1
targetCPUUtilizationPercentage: 10
scaleTargetRef: 대상설정
minReplicas: 최소pod
maxReplicas: 최대pod
targetCPUUtilizationPercentage: CPU 사용 임계치 %로설정 넘어서면 업스케일 동작
while true; do wget q -O https://rolling.test.com:30100/coin/list; done
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
git clone https://github.com/kubernetes-incubator/metrics-server.git
cd metrics-server/
kubectl create -f deploy/1.8+/
[root@tweb01 ~] kubectl get –raw “/apis/metrics.k8s.io/v1beta1/nodes” {“kind”:”NodeMetricsList”,”apiVersion”:”metrics.k8s.io/v1beta1”,”metadata”:{“selfLink”:”/apis/metrics.k8s.io/v1beta1/nodes”},”items”:[{“metadata”:{“name”:”tweb01.freebex.com”,”selfLink”:”/apis/metrics.k8s.io/v1beta1/nodes/tweb01.freebex.com”,”creationTimestamp”:”2018-06-28T07:27:00Z”},”timestamp”:”2018-06-28T07:26:00Z”,”window”:”1m0s”,”usage”:{“cpu”:”116m”,”memory”:”2454816Ki”}},{“metadata”:{“name”:”tweb02.freebex.com”,”selfLink”:”/apis/metrics.k8s.io/v1beta1/nodes/tweb02.freebex.com”,”creationTimestamp”:”2018-06-28T07:27:00Z”},”timestamp”:”2018-06-28T07:26:00Z”,”window”:”1m0s”,”usage”:{“cpu”:”76m”,”memory”:”1818256Ki”}}]}
vi /etc/kubernetes/manifests/kube-controller-manager.yaml
controller-manager 옵션에 추가
그래도 unknown이 나오면 재실행 해보고 부하를 줘보고 기다려보면 나온다.